Editor’s Note : In this article, guest contributor Paul Currion looks at the potential for crowdsourcing data during large-scale humanitarian emergencies, as part of our "Deconstructing Mobile" series. Paul is an aid worker who has been working on the use of ICTs in large-scale emergencies for the last 10 years. He asks whether crowdsourcing adds significant value to responding to humanitarian emergencies, arguing that merely increasing the quantity of information in the wake of a large-scale emergency may be counterproductive. Instead, the humanitarian community needs clearly defined information that can help in making critical decisions in mounting their programmes in order to save lives and restore livelihoods. By taking a close look at the data collected via Ushahidi in the wake of the Haiti earthquake, he concludes that crowdsourced data from affected communities may not be useful for supporting the response to a large-scale disaster.
: In this article, guest contributor Paul Currion looks at the potential for crowdsourcing data during large-scale humanitarian emergencies, as part of our "Deconstructing Mobile" series. Paul is an aid worker who has been working on the use of ICTs in large-scale emergencies for the last 10 years. He asks whether crowdsourcing adds significant value to responding to humanitarian emergencies, arguing that merely increasing the quantity of information in the wake of a large-scale emergency may be counterproductive. Instead, the humanitarian community needs clearly defined information that can help in making critical decisions in mounting their programmes in order to save lives and restore livelihoods. By taking a close look at the data collected via Ushahidi in the wake of the Haiti earthquake, he concludes that crowdsourced data from affected communities may not be useful for supporting the response to a large-scale disaster.
1. The Rise of Crowdsourcing in Emergencies
Ushahidi, the software platform for mapping incidents submitted by the crowd via SMS, email, Twitter or the web, has generated so many column inches of news coverage that the average person could be mistaken for thinking that it now plays a central role in coordinating crisis responses around the globe. At least this is what some articles say, such as Technology Review's profile of David Kobia, Director of Technology Development for Ushahidi. For most people, both inside and outside the sector, who lack the expertise to dig any deeper, column inches translate into credibility. If everybody's talking about Ushahidi, it must be doing a great job – right?
Maybe.
Ushahidi is the result of three important trends:
- Increased availability and utility of spatial data;
- Rapid growth of communication infrastructure, particularly mobile telephony; and
- Convergence of networks based on that infrastructure on Internet access.
Given those trends, projects like Ushahidi may be inevitable rather than unexpected, but inevitability doesn't give us any indication of how effective these projects are. Big claims are made about the way in which crowdsourcing is changing the way in which business is done in other sectors, and now attention has turned to the humanitarian sector. John Della Volpe's short article in the Huffington Post is an example of such claims:
"If a handful of social entrepreneurs from Kenya could create an open-source "social mapping" platform that successfully tracks and sheds light on violence in Kenya, earthquake response in Chile and Haiti, and the oil spill in the Gulf -- what else can we use it for?"
The key word in that sentence is “successfully”. There isn’t any evidence that Ushahidi “successfully” carried out these functions in these situations; only that an instance of the Ushahidi platform was set up. This is an extremely low bar to clear to achieve “success”, like claiming that a new business was successful because it had set up a website. There has lately been an unfounded belief that the transformative effects of the latest technology are positively inevitable and inevitably positive, simply by virtue of this technology’s existence.
2. What does Successful Crowdsourcing Look Like?
To be fair, it's hard to know what would constitute “success” for crowdsourcing in emergencies. In the case of Ushahidi, we could look at how many reports are posted on any given instance – but that record is disappointing, and the number of submissions for each Ushahidi instance is exceedingly small in comparison to the size of the affected population – including Haiti, where Ushahidi received the most public praise for its contribution.
In any case, the number of reports posted is not in itself a useful measure of impact, since those reports might consist of recycled UN situation reports and links to the Washington Post's “Your Earthquake Photos” feature. What we need to know is whether the service had a significant positive impact in helping communities affected by disaster. This is difficult to measure, even for experienced aid agencies whose work provides direct help. Perhaps the best we can do is ask a simple question: if the system worked exactly as promised, what added value would it deliver?
As Patrick Meier, a doctoral student and Director of Crisis Mapping and Strategic Partnerships for Ushahidi has explained, crowdsourcing would never be the only tool in the humanitarian information toolbox. That, of course, is correct and there is no doubt that crowdsourcing is useful for some activities – but is humanitarian response one of those activities?
A key question to ask is whether technology can improve information flow in humanitarian response. The answer is that it absolutely can, and that's exactly what many people, including this author, have been working on for the last 10 years. However, it is a fallacy to think that if the quantity of information increases, the quality of information increases as well. This is pretty obviously false, and, in fact, the reverse might be true.
From an aid worker’s perspective, our bandwidth is extremely limited, both literally and metaphorically. Those working in emergency response – official or unofficial, paid or unpaid, community-based or institution-based, governmental or non-governmental – don't need more information, they need better information. Specifically, they need clearly defined information which can help them to make critical decisions in mounting their programmes in order to save lives and restore livelihoods.
I wasn't involved with the Haiti response, which made me think that perhaps my doubts about Ushahidi were unfounded and that perhaps the data they had gathered could be useful. In the course of discussions on Patrick Meier's blog, I suggested that the best way for Ushahidi to show my position was wrong would be to present a use case to show how crowdsourced data could be used (as an example) by the Information Manager for the Water, Sanitation and Hygiene Coordination Cluster, a position which I filled in Bangladesh and Georgia. Two months later, I decided to try that experiment for myself.
3. In Which I Look At The Data Most Carefully
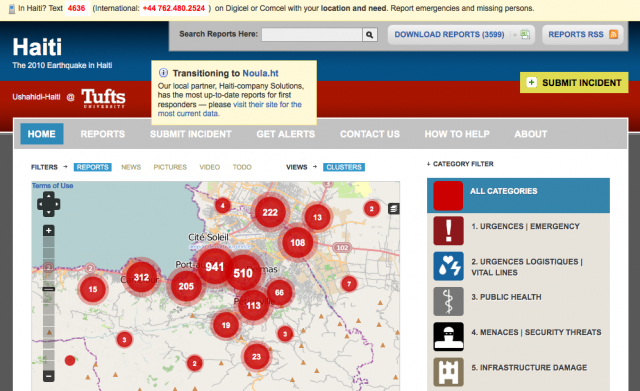
The only crowdsourced data I have is the Ushahidi dataset for Haiti, but since Haiti is claimed as a success, that seemed like to be a good place to start. I started by downloading and reading through the dataset – the complete log of all reports posted in Ushahidi. It was a mix of two datastreams:
- Material published on the web or received via email, such as UN sitreps, media reports, and blog updates, and
- Messages sent in by the public via the 4636 SMS shortcode established during the emergency.
I was struck by two observations:
- One of the claims made by the Ushahidi team is that its work should be considered an additional datastream for a id workers. However, the first datastream is simply duplicating information that aid workers are already likely to receive.
- The 4636 messages were a novel datastream, but also the outcome of specific conditions which may not hold in places other than Haiti. The fact that there is a shortcode does not guarantee results, as can be seen in the virtually empty Pakistan Ushahidi deployment.
I considered that perhaps the 4636 messages could demonstrate some added value. They fell into three broad categories: the first was information about the developing situation, the second was people looking for information about family or friends missing after the earthquake, and the third and by far the largest, was general requests for help.
I tried to imagine that I had been handed this dataset on my deployment to Haiti. The first thing I would have to do is to read through it, clean it up, and transcribe it into a useful format rather than just a blank list. This itself would be a massive undertaking that can only be done by somebody on the ground who knows what a useful format would be. Unfortunately, speaking from personal experience, people on the ground simply don't have time for that, particularly if they are wrestling with other data such as NGO assessments or satellite images.
For the sake of argument, let's say that I somehow have the time to clean up the data. I now have a dataset of messages regarding the first three weeks of the response. 95% of those messages are for shelter, water and food. I could have told you that those would be the main needs even before I arrived in position, so that doesn't add any substantive value. On top of that, the data is up to 3 weeks old: I'd have to check each individual report just to find out just whether those people are still in the place that they were when they originally texted, and whether their needs have been met.
Again for the sake of argument, let's say that I have a sufficient number of staff (as opposed to zero, which is the number of staff you usually have when you're an information manager in the field) and they've checked every one of those requests. Now what? There are around 3000 individual “incidents” in the database, but most of those contain little to no detail about the people sending them. How many are included in the request, how many women, children and old people are there, what are their specific medical needs, exactly where they are located now – this is the vital information that aid agencies need to do their work, and it simply isn't there.
Once again for the sake of argument, let's say that all of those reports did contain that information – could I do something with it? If approximately 1.5 million people were affected by the disaster, those 3000 reports represent such a tiny fraction of the need that they can't realistically be used as a basis for programming response activities. One of the reasons we need aid agencies is economies of scale: procuring food for large populations is better done by taking the population as a whole. Individual cases, while important for the media, are almost useless as the basis for making response decisions after a large-scale disaster.
There is also this very basic technical question: once we have this crowdsourced data, what do we do with? In the case of Ushahidi, it was put on a Google Maps mash-up – but this is largely pointless for two reasons. First, there's a simple question of connectivity. Most aid workers and nearly all the population won't have reliable access to the Internet, and where they do, won't have time to browse through Google Maps. (It's worth noting that this problem is becoming less important as Internet connectivity, including the mobile web, improves globally – but also that the places and people prone to disasters tend to be the last to benefit from that connectivity.)
Second, from a functional perspective, the interface is rudimentary at best. The visual appeal of Ushahidi is similar to that of Powerpoint, casting an illusion of simplicity over what is, in fact, a complex situation. If I have 3000 text messages saying "I need food and water and shelter”, what added value is there from having those messages represented as a large circle on a map? The humanitarian community often lacks the capacity to analyse spatial data, but this map has almost no analytical capacity. The clustering of reports (where larger bubbles correspond to the places that most text messages refer to) may be a proxy for locations with the worst impact; but a pretty weak proxy derived from a self-selecting sample.
In the end, I was reduced to bouncing around the Ushahidi map, zooming in and out on individual reports – not something I would have time to do if I was actually in the field. Harsh as it sounds, my conclusion was that the data that crowdsourcing of this type is capable of collecting in a large-scale disaster response is operationally useless. The reason for this has nothing to do with Ushahidi, or the way that the system was implemented, but with the very nature of crowdsourcing itself.
4. Crowdsourcing Response or Digital Voluntourism?
One of the key definitions of “crowdsourcing” was provided by Jeff Howe in a Wired article that originally popularised the term: taking “a job traditionally performed by a designated agent (usually an employee) and outsourcing it to an undefined, generally large group of people in the form of an open call.” In the case of Haiti, part of the reason why people mistakenly thought crowdsourcing was successful, was because there were two different “crowds” being talked about.
The first was the global group of volunteers who came together to process the data that Ushahidi presented on its map. By all accounts, this was definitely a successful example of crowdsourcing as per Howe's definition. We can all agree that this group put a lot of effort into their work. However, the end result wasn’t especially useful. Furthermore, most of those volunteers won't show up for the next response – and in fact they didn't for Pakistan.
The media coverage of Ushahidi focuses mainly on this first crowd – the group of volunteers working remotely. Yet, the second crowd is much more important: the affected community. Reading through the Ushahidi data was heartbreaking, indeed. But we already knew that people needed food, water, shelter, medical aid – plus a lot more things that they wouldn't have been thinking of immediately as they stood in the ruins of their homes. In the Ushahidi model, this is the crowd that provides the actual data, the added value, but the question is whether crowdsourced data from affected communities could be useful from an operational perspective of organising the response to a large-scale disaster.
The data that this crowd can provide is unreliable for operational purposes for three reasons. First, you can't know how many people will contribute their information, a self-selection bias that will skew an operational response. Second, the information that they do provide must be checked – not because affected populations may be lying, but because people in the immediate aftermath of a large-scale disaster do not necessarily know all that they specifically need or may not provide complete information. Third, the data is by nature extremely transitory, out-of-date as soon as it's posted on the map.
Taken together, these three mean that aid agencies are going to have to carry out exactly the same needs assessments that they would have anyway – in which case, what use was that information in the first place?
5. Is Crowdsourcing Raising Expectations That Cannot be Met?
Many of the critiques that the crowdsourcing crowd defend against are questions about how to verify the accuracy of crowdsourced information, but I don't think that's the real problem. It's the nature of an emergency that all information is provisional. The real question is whether it's useful.
So to some extent those questions are a distraction from the real problems: how to engage with affected communities to help them respond to emergencies more effectively, and how to coordinate aid agencies to ensure and effective response. On the face of it, crowdsourcing looks like it can help to address those problems. In fact, the opposite may be true.
Disaster response on the scale of the Haiti earthquake or the Pakistan floods is not simply a question of aggregating individual experiences. Anecdotes about children being pulled from rubble by Search and Rescue teams are heart-warming and may help raise money for aid agencies but such stories are relatively incidental when the humanitarian need is clean water for 1 million people living in that rubble. Crowdsourced information – that is, information voluntarily submitted in an open call to the public – will not ever provide the sort of detail that aid agencies need to procure and supply essential services to entire populations.
That doesn't mean that crowdsourcing is useless: based on the evidence from Haiti, Ushahidi did contribute to Search and Rescue (SAR). The reason for that is because SAR requires the receipt of a specific request for a specific service at a specific location to be delivered by a specific provider – the opposite of crowdsourcing. SAR is far from being a core component of most humanitarian responses, and benefits from a chain of command that makes responding much simpler. Since that same chain of command does not exist in the wider humanitarian community, ensuring any response to an individual 4636 message is almost impossible.
This in turn raises questions of accountability – is it wholly responsible to set up a shortcode system if there is no response capability behind it, or are we just raising the expectations of desperate people?
6. Could Crowdsourcing Add Value to Humanitarian Efforts?
Perhaps it could. However, the problem is that nobody who is promoting crowdsourcing currently has presented convincing arguments for that added value. To the extent that it's a crowdsourcing tool, Ushahidi is not useful; to the extent that it's useful, Ushahidi is not a crowdsourcing tool.
To their credit, this hasn't gone unnoticed by at least some of the Ushahidi team, and there seems to be something of a retreat from crowdsourcing, described in this post by one of the developers, Chris Blow:
One way to solve this: forget about crowdsourcing. Unless you want to do a huge outreach campaign, design your system to be used by just a few people. Start with the assumption that you are not going to get a single report from anyone who is not on your payroll. You can do a lot with just a few dedicated reporters who are pushing reports into the system, curating and aggregating sources."
At least one of the Ushahidi team members now talks about “bounded crowdsourcing” which is a nonsensical concept. By definition, if you select the group doing the reporting, they're not a crowd in the sense that Howe explained in his article. This may be an area where Ushahidi would be useful, since a selected (and presumably trained) group of reporters could deliver the sort of structured data with more consistent coverage that is actually useful – the opposite of what we saw in Haiti. Such an approach, however, is not crowdsourcing.
Crowdsourcing can be useful on the supply side: for example, one of the things that the humanitarian community does need is increased capacity to process data. One of the success stories in Haiti was the work of the OpenStreetMap (OSM) project, where spatial data derived from existing maps and satellite images was processed remotely to build up a far better digital map of Haiti than existed previously. However, this processing was carried out by the already existing OSM community rather than by the large and undefined crowd that Jeff Howe described.
Nevertheless this is something that the humanitarian community should explore, especially for data that has a long-term benefit for affected countries (such as core spatial data). To have available a recognised group of data processors who can do the legwork that is essential but time-consuming would be a real asset to the community – but there we've moved away from the crowd again.
7. A Small Conclusion

My critique of crowdsourcing – shared by other people working at the interface of humanitarian response and technology – is not that it is disruptive to business as usual. My critique is that it doesn't work – not just that it doesn't work given the constraints of the operational environment (which Ushahidi's limited impact in past deployments shows to be largely true), but that even if the concept worked perfectly, it still wouldn't offer sufficient value to warrant investing in.
Unfortunately, because Ushahidi rests its case almost entirely on the crowdsourcing concept, this article may be interpreted as an attack on Ushahidi and the people working on it. However, all of the questions I've raised here are not directed solely at Ushahidi (although I hope that there will be more debate about some of the points raised) but hopefully will become part of a wider and more informed debate about social media in general within the humanitarian community.
Resources are always scarce in the humanitarian sector, and the question of which technology to invest in is a critical one. We need more informed voices discussing these issues, based on concrete use cases because that's the only way we can test the claims that are made about technology. For while the tools that we now have at our disposal are important, we have a responsibility to use them for the right tasks.
Image credit: Urban Search and Rescue Team, with assistance from U.S. military personnel, coordinate plans before a search and rescue mission in order to find survivors in Port-au-Prince. U.S. Navy Photo.
Mobile Use by Micro & Small Enterprises, Wedding Cakes and more
Digital Customization: Mobile Wedding venues in Chicago are offering apps or mobile-responsive websites where couples can customize their venue layout, pick décor themes, and even select lighting moods.
This level of customization ensures the couple can envision and shape their special day in real-time.
| “If all You Have is a Hammer” - How Useful is Humanitarian Crowdsourcing? data sheet 21260 Views | |
|---|---|
| Countries: | Haiti |

A statistical examination of the Haiti dataset
A couple teams of statisticians have looked into the question of whether the locations of the Haiti SMS message could be used to know the locations with the most building damage, in order to guide further damage assessment efforts. There's a debate over the results that makes a good complement to the discussion here about Paul's article: The original study described by Patrick Meier, and a reanalysis that questions the conclusions.
Its not all bad
The discussion posted on http://www.mobileactive.org/ written by Paul Currion raises some interesting points about the use of technology in a disaster and humanitarian context. Haiti has become recognized as the techno disaster where lots of players entered the field and tested out the latest in technologies. Ushahidi wasn’t the only group that arrived. Organizations like TRF using the INSTEADD system and Frontline also turned up and tried out their wares as did others. I also turned up and was able, on some level, to hang with some of the operators in the response. I think all players came with the right thing in mind, to add to the response and try to the best of their ability to help out.
One thing that has been proven - all were capable of building systems that worked; The technology was successful. The Ushahidi system, allowed SMS in and out, emails, photos and videos to be uploaded onto a Google map interface that could then be viewed by the rest of the world. Impressive stuff! I personally showed the system to colleagues and discussed ways that we could also use it in the Organization. The same can be said with the Frontline system, a simpler model. If used properly, it could be just as effective. We can all say that what was developed from a technological perspective was truly amazing and that all parties should be recognized for their achievements.
From a more practical use by a humanitarian I have the following to add to the discussion. The problem I see with the systems is that people are relying totally on the technology to do the job. Unfortunately this doesn’t work. The crowd sourcing idea/system is a good one. If it is going to be used in a disaster or humanitarian context, it just needs to be adapted to suit the situation. I think the Ushahidi team came closer to this in the end when they started working with a local provider.
There needs to be a human interface, a team in place who can respond to the information received from the recipient of the original SMS, that is, follow up. This will at least deal with some of the expectation that is developed when people receive a SMS asking them for information. The other issue is managing the information. If you advertise the system nationally as a service, usually people will respond because of the expectation that it will help them, so what you end up with is too much information to do anything with. The only real way this can be managed is to target areas geographically, so you know how many people will be needed to deal with the inflow of information. This model works alongside the technology. It is necessary to manage the system from a small core and build from there as opposed to trying to take on too much in the initial deployment.
A project in Aceh called the Community Outreach Program (COP), used different technologies in the implementation of an advocacy program for the affected populations in the Aceh region. The SMS component proved to be very successful as a way to communicate with people and receive information relating to their needs or issues. What made the program a success was the face to face component. Every SMS received would generate an automated response, a follow up phone call. If the issue couldn’t be dealt with over the phone, a team was sent out to discuss the issues in the community. We used a very basic system developed by a local programmer with a poor modem. If we had a system in place like the Ushaidi platform, we would have been very happy, and probably would have been able to create a bit more attention and hype around the already successful project. Although the COP program was more a development program and not used in a disaster context it is possible to develop this model further to use in a disaster situation.
I would say that the systems all have a place in the Humanitarian cycle, they just need to work alongside the Humanitarian sector to develop the implementation process further. People do have access to mobile phones in disaster prone countries and we should understand this and open up communication channels with them.
Personally I look forward to working more with these guys in the future and looking at ways to utilise these systems.
willrogerinfo.com
Apologies for any offense to 4636
Robert:
Thanks for commenting, although I'm sorry that you've taken this article personally. It wasn't intended to be a personal attack on anybody involved, and I have a huge amount of admiration for what you managed to achieve in a short space of time.
Currion is right that only people on the ground can define what is 'actionable' or useful information. Then he simply imagines himself on the ground after looking at 1-2% of a data dump and not talking to a single person who actually used the data.
Robert, I'd love to talk to the people who used the data, so perhaps you can provide me with some of their details? The reason for imagining myself on the ground is because, if I hadn't been in South Sudan at the time, I probably would have been on the ground. I thought back to past experiences when I've worked in similar positions in other countries over the last decade, and based my analysis of what would be useful data on that. I'm unsure why you have such a problem with that.
The author has spent more time replying to comments here then actually working on crowdsourcing platforms or talking to aid workers that rely on them.
That's not quite true, since I spent several years working on Aid Workers Network (a crowdsourced approach to knowledge management) and Sahana (an open source platform which I believe is now working with Ushahidi). I also asked a few colleagues who were in Haiti for opinions: some replied that they hadn't heard of it, and some (like Mark of IOM, commenting below) felt the story that was being told to headquarters / media / donors didn't quite match up with the impact on the ground.
The reason that I've spent the time replying to comments here is because this is the debate that I hoped the article would generate, and I promised myself that I would respond to every comment. I had hoped to continue the discussion on your blog, but unfortunately you refused to answer my first question, and then closed the comments section. However I accept that I may not have the necessary background knowledge to make a useful analysis, so perhaps you can help me?
From your comments here and on your blog, it obviously frustrates you when people (like me) make claims that aren't backed up by the evidence. The front page of Mission 4636 says that “The service was able to direct emergency response teams to save hundreds of people, and direct the first food, water and medicine to tens of thousands.” Now I know that you wouldn't make such a claim without evidence, so can you help to correct me by providing it?
the view from the ground is different?
Mark:
Thanks for your contribution, it's interesting to hear from IOM's perspective. I opened the article with brief discussion of the media coverage of Ushahidi for exactly the reason you give: the claims made about crowdsourcing by the Ushahidi team simply do not fit with what actually happened on the ground.
But it seemed that this narrative first had to follow the irritating old pattern of exaggerated claims, followed by those claims being shot down, followed by - at last - a rationale discussion of what worked and what didn't.
I couldn't agree more. I've seen this process happen at least 4 times in the last 10 years when an exciting new technology is introduced. Like you, I am very much hoping that we are moving now to the rational discussion of what worked and what didn't.
Unfortunately it seems that the people involved in crowdsourcing are not so interested – from Robert Munro's (of 4636) comments here and on his own blog, he doesn't appear to be interested in having that rational discussion. As for Ushahidi, they appear to be ignoring this article, which is a shame; their contribution to the discussion would be extremely valuable.
On Misunderstanding 2
Ugotitwrong:
If you want the real story of crowdsourcing and Ushahidi in Haiti, look here, written by one of the guys who actually did it.
I think you've misunderstood my argument here. I'm not disputing that Robert's account of their work is the real story; I'm questioning what the impact of that work was in operational terms, primarily for humanitarian organisations but also for affected communities.
On Misunderstanding...
Chris:
I guess I knew that this article would be misunderstood (in some cases deliberately), especially the specific phrase about Ushahidi that you quoted. However I tried to make it clear (not least in the title) that I am talking about a very specific topic and not generalising about crowdsourcing (or any of the tools associated with it); and I've tried to clarify in the text and these comments that I do believe that crowdsourcing can be useful in some areas.
I also think it could be made useful for a humanitarian response by crowdsourcing the aggregation, categorisation, sorting, grouping and filing of reports, much as this is done for bug reports in the open source software community.
I think that's where we differ. There's a tendency among some people to think that the techniques and terminology of software development translate readily into other processes, but they don't. The question is not whether we can process the data, the question is whether that data is useful enough to warrant investing in this particular process. Once again: I'm open to persuasion about the value of crowdsourcing in humanitarian operations, it's just that nobody seems to be interested in making the case.
You also mention that crowdsourcing may be useful in e.g. Search and Rescue. Two things on that: first, we don't have any concrete evidence yet that it was useful for SAR. I know that Robert, Patrick Meier and others disagree based on their experience, and they're perfectly entitled to: but personal experience is not particularly good evidence if it isn't backed up by something more concrete, and the supporting anecdotes look suspiciously vague to me.
fantastic discussion
Hi all. This is a fantastic discussion. Thanks for getting it going Paul.
I want to second whomever said "it's early days" in one of the comments. And it seems like there may be a conflation of the story in the news and the internal evaluation of efficacy.
I don't know the folks at Ushahidi well - but I do know that they're committed, passionate, and smart people. And i'll take bets that they take efficacy very seriously - as in #1 priority - and that their course is one of constant shifts towards improving it. And being effective as a social enterprise is not *exclusively* about results on the ground (but don't take that the wrong way, b/c it's all that matters at the end of the day) - but in order to get good results on the ground, you've got to drive excitement around your organization and the potential of your big idea - and to celebrate the small incremental successes - while being realistic about the shortcomings.
So the story in the news is about the excitement around being able to get meaningfully involved in rescue efforts from your cubicle. That's really exciting - and the press around that idea is right to be enthusiastic about the potential there.
Paul, as you mention - this potential has got to convert into meaningful impact on the ground at some point. And while your focus on the importance of these results is right on - give it some time. Let's point at the weaknesses and focus in on the opportunities (which you do touch on in the piece). This process is one of experimentation, adjustment, experiment, adjust, repeat. All fantastically world changing technologies evolved in this iterative fashion (including humanity, of course).
ben rigby
cto and co-founder, extraordinaries
now at: www.sparked.com
If you want the real story
If you want the real story of crowdsourcing and Ushahidi in Haiti, look here, written by one of the guys who actually did it. With the real numbers, not made up hypotheticals:
http://www.junglelightspeed.com/evaluating-crowdsourcing/
Counterpoints
Hi Paul,
Thanks for a very interesting, detailed and thought-provoking article, and for taking the time to actually try using Ushahidi for your intended purpose in order to report accurately on it.
I think your statement "To the extent that it's a crowdsourcing tool, Ushahidi is not useful; to the extent that it's useful, Ushahidi is not a crowdsourcing tool" could potentially be taken out of context, and that worries me. As you said elsewhere, it IS useful (for Search and Rescue), but maybe not for planning a humanitarian response.
I also think it could be made useful for a humanitarian response by crowdsourcing the aggregation, categorisation, sorting, grouping and filing of reports, much as this is done for bug reports in the open source software community.
I also take issue with your conclusion:
We can only judge whether they have done an excellent job based on the performance of that tool. The point of this article is that so far that tool has not performed well, and that I find it difficult to see how it can perform well, in the sense of having a significant positive impact on the lives of people affected by disaster.
You already pointed out one such use yourself: in assisting Search and Rescue operations. This may well have such an impact.
You haven't investigated the other "many things" that the tool does. If it does allow crowdsourcing in a disaster (and it seems to) then it may do so excellently. Even if crowdsourcing happens to be useless in that particular disaster, or is not being used for a useful purpose, one can't infer that it's always useless, any more than a spoon which is useless at opening a tin can.
Anyway, enough of my uninformed ranting :)
Cheers, Chris.
This is not a valid review
This whole article is based on false premises from a very poorly designed review. Currion is right that only people on the ground can define what is 'actionable' or useful information. Then he simply imagines himself on the ground after looking at 1-2% of a data dump and not talking to a single person who actually used the data. He still hasn't. This is not 'digging deeper' - it is irresponsible and misleading. The author has spent more time replying to comments here then actually working on crowdsourcing platforms or talking to aid workers that rely on them. More here: http://crowdscientist.com/evaluating-crowdsourcing/
Post new comment